You're the Lead Engineer
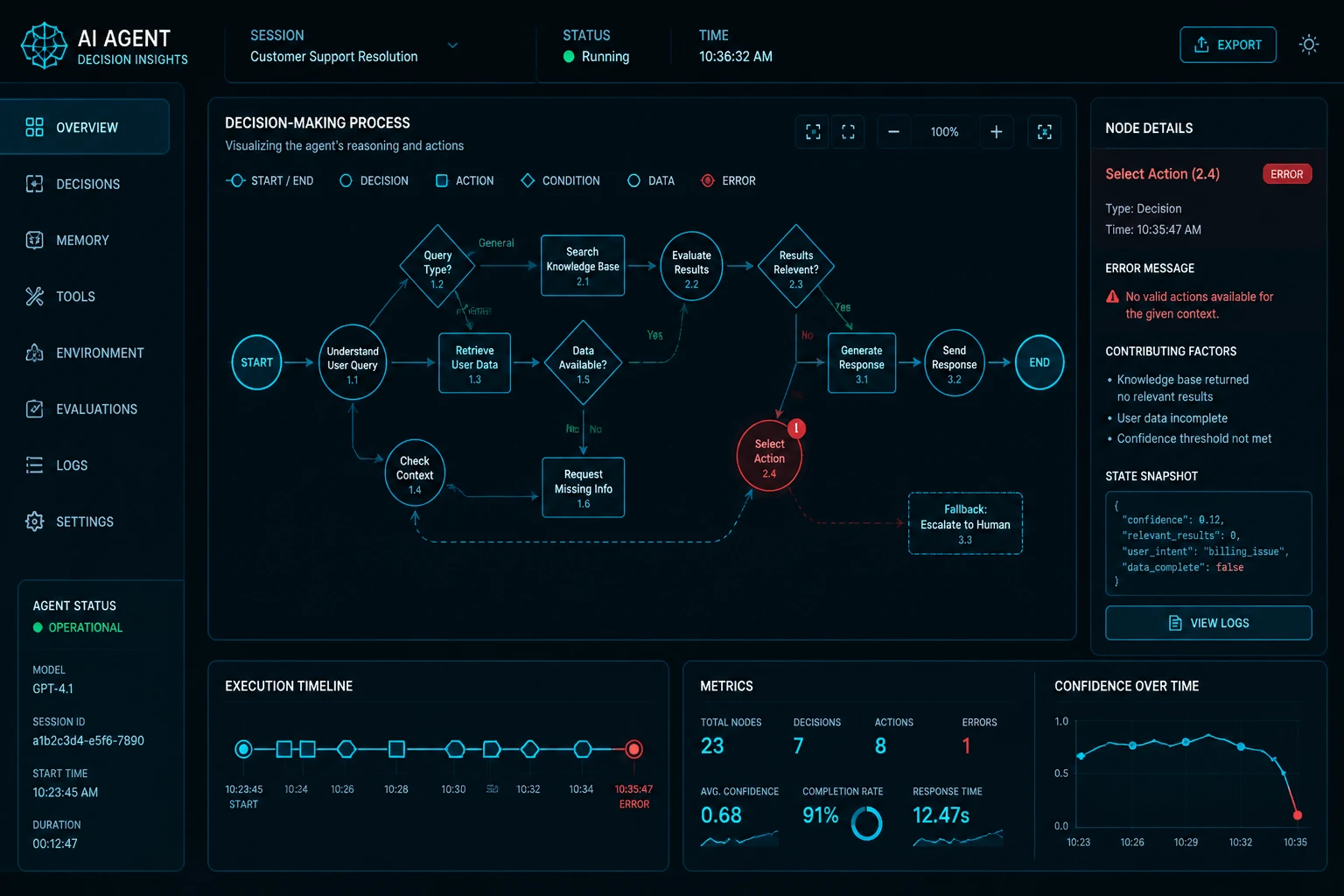
What's in this lesson
We explore how modern AI agent systems are measured, tested, and validated. Topics include evaluation frameworks (SWE-bench, GAIA), task success metrics, trajectory analysis, LLM-as-a-judge, and reliability testing.
Why this matters
Building an agent is easy; ensuring it consistently performs as intended is hard. Evaluation is the foundation for improving reliability, identifying failure modes, and ensuring agents operate effectively at scale.
Imagine your company just deployed a customer service agent to book flights. On day one, a customer asked for "the cheapest flight to Tokyo arriving before 5 PM." The agent successfully booked a flight to Tokyo, but it arrives at 11 PM and costs $400 more than the cheapest option.
How do you measure this failure? Is it a complete failure because the constraints weren't met, or a partial success because a flight was booked? How do you find out where the reasoning broke down?
Activity: In this scenario, what is the most critical first step to prevent this from happening again?
Fundamentals of Evaluation
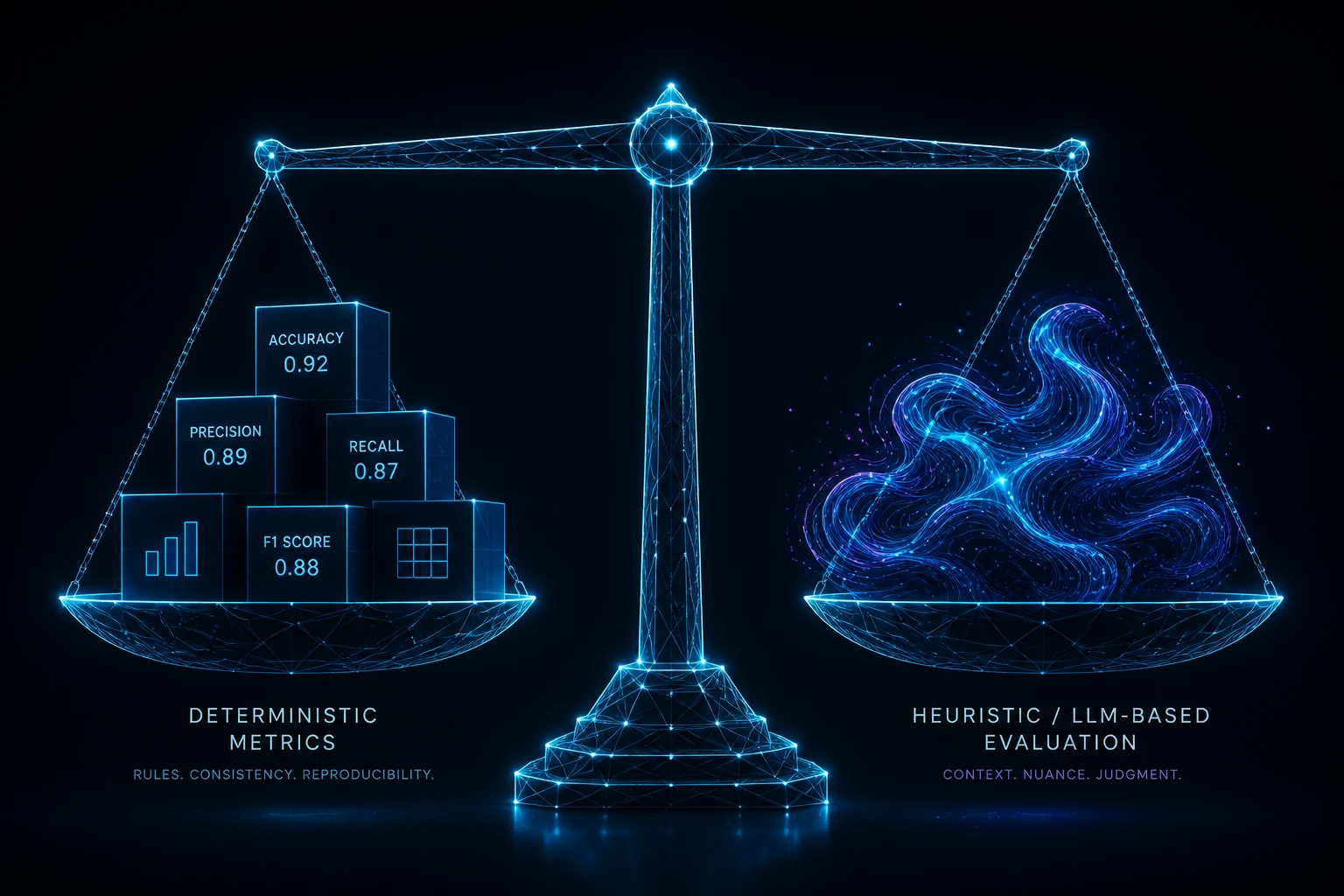
Evaluating standard LLM generation (like summarizing a document) relies on text similarity metrics or stylistic judgments. Evaluating an Agent is fundamentally different because agents take actions over time to change an environment.
Agent evaluation splits into two primary paradigms:
1. Deterministic Metrics
Exact, rule-based checks on the final state of the environment. Example: Did the row get inserted into the database? Did the python script pass the unit tests? These are perfectly reliable but hard to build for open-ended tasks.
2. Heuristic & LLM-based Metrics
Using flexible grading rules or another LLM ("LLM-as-a-judge") to grade the outcome. Example: Was the email draft polite and accurate? This scales well to open-ended tasks but introduces subjectivity and potential grading errors.
Knowledge Check
Which of the following is an example of a deterministic evaluation metric for a coding agent?
Task Success & Outcome Metrics
The ultimate goal of an agent is to succeed at its task. But "success" isn't always binary.
When measuring task outcomes, evaluators often calculate:
- Success Rate: The percentage of tasks completed perfectly (Binary Pass/Fail).
- Partial Success: Awarding points for achieving sub-goals (e.g., found the flight, but failed to book it).
Interactive: Set the Threshold
Adjust the slider to see how partial credit changes the perception of an agent's reliability.
Trajectory Evaluation
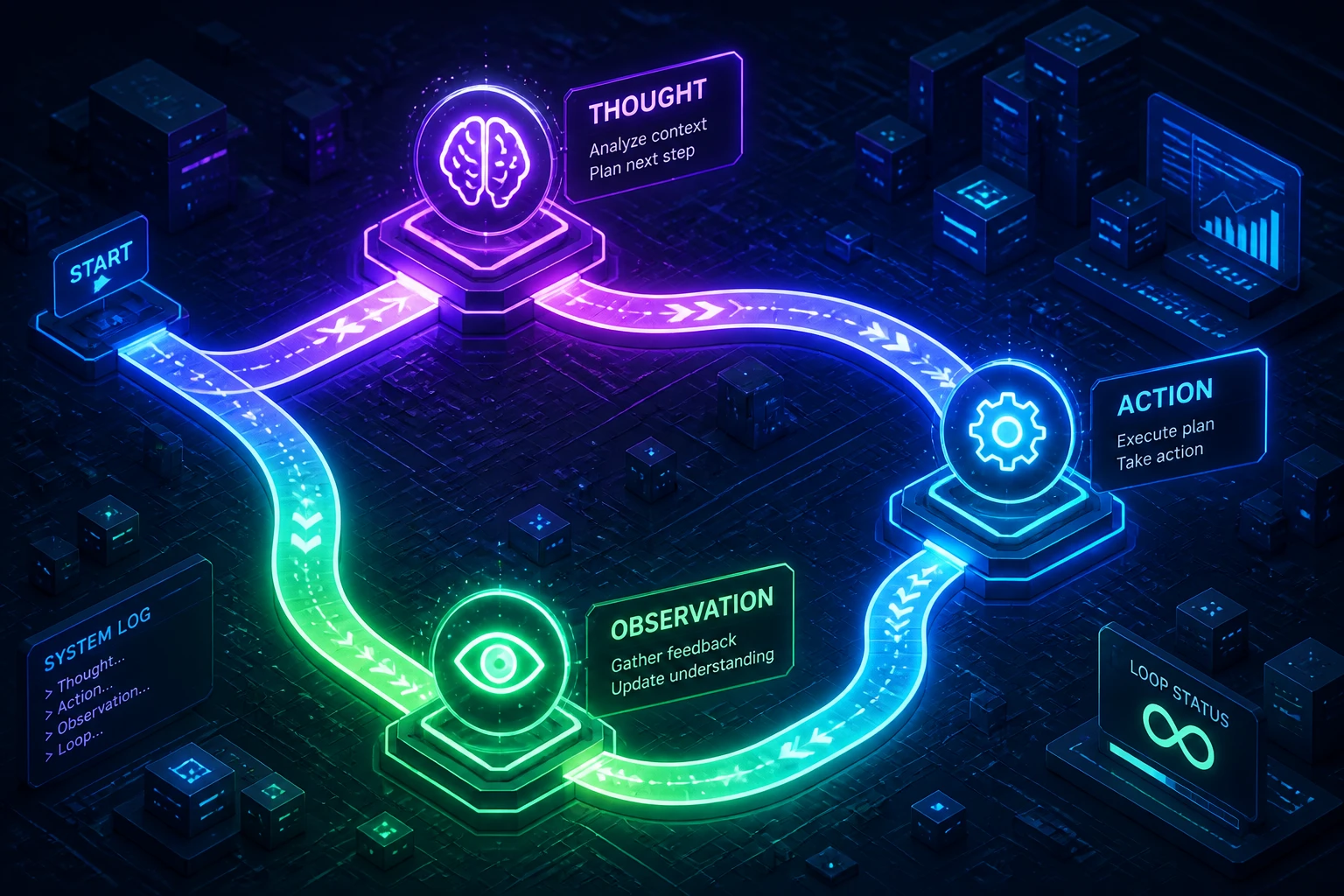
An outcome metric tells you if the agent succeeded. Trajectory evaluation tells you how and why.
A trajectory is the sequence of steps an agent takes. In a ReAct (Reasoning + Acting) framework, this consists of loops of Thought, Action (tool call), and Observation (tool result).
By analyzing trajectories, we can detect inefficiencies that outcome metrics miss:
- Repetition loops: The agent calling the same tool with the same failed arguments 5 times.
- Hallucinated actions: The agent trying to use a tool that doesn't exist.
- Inefficient paths: Taking 15 steps to do a 2-step task.
Tool-Use & Capability Assessment
Agents interact with the world via Tools (APIs, calculators, browsers). Evaluating tool use requires checking the exact JSON or arguments the agent generates.
Diagnostic Exercise
Review the agent's trajectory trace below. Click on the node where the agent made a critical tool-use error.
Knowledge Check
Why is trajectory evaluation important even when an agent successfully completes a task?
Workflow Performance Metrics

In production, an agent must be more than just accurate; it must be practical. Evaluating the workflow involves operational metrics.
⏱️ Latency
Total time to task completion. Long trajectories drastically increase Time to First Byte (TTFB).
💸 Cost
Total tokens consumed. Agents often send massive context windows back and forth iteratively.
📦 Context Efficiency
How quickly the agent hits the context limit. Does it summarize past observations, or append them endlessly?
Failure Analysis & Error Categorization
When an agent fails, classifying the error is crucial for debugging. Click the error types to learn more.
The agent outputs invalid JSON or fails to follow the required schema for a tool call. Often fixed with JSON mode, structured outputs, or better system prompts.
The agent executes tools perfectly but makes a bad plan. (e.g., trying to divide by zero, or searching for 2022 news to answer a 2024 question).
The "execute-fail-fix" loop. The agent encounters an API error, apologizes to itself, tries the exact same broken API call, and repeats until the token limit is reached.
The agent assumes it has finished the task before verifying the results. (e.g., "I have written the code. Task complete." without running the tests to see if it works).
Automated Pipelines & LLM-as-a-Judge

To run evaluations continually in a CI/CD pipeline, humans are too slow. Instead, the industry uses LLM-as-a-Judge.
You use a highly capable model (like GPT-4) to evaluate the trace and outcome of your production agent. You provide the judge with a grading rubric.
Judge Prompt Template
[System] You are an expert evaluator.
Review the agent's trajectory and the user request.
Request: {user_req}
Trajectory: {agent_trace}
Did the agent solve the user's problem without violating safety rules?
Score 1 for pass, 0 for fail. Explain your reasoning.
Knowledge Check
What is a known risk or limitation of using the "LLM-as-a-Judge" technique?
Human-in-the-Loop (HITL) Evaluation
Despite automated judges, Human-in-the-Loop (HITL) evaluation remains the gold standard for ground truth. Humans review a subset of agent actions to catch subjective nuances, safety violations, or "vibe" issues that automated judges miss.
Interactive: Be the Human Judge
Task: "Draft a friendly email rejecting a candidate." Which agent response is better?
"Hi John, Unfortunately we are rejecting your application. You do not meet the skills required. Goodbye."
"Dear John, Thank you for taking the time to apply. While we were impressed by your background, we have decided to move forward with another candidate. We wish you the best."
Agent Benchmarking Frameworks

To compare different agents fairly, researchers have built standardized benchmarks. These are simulated environments with pre-defined tasks and deterministic success criteria.
- SWE-bench: Tests coding agents. Agents are given a real GitHub issue from a Python repository and must write a pull request to fix it. Success = passing the repo's unit tests.
- WebArena: Tests web navigation agents. Agents operate in a simulated e-commerce, forum, or CMS environment to accomplish tasks like "buy the cheapest blue shirt."
- GAIA: Tests general assistant agents. Questions require reasoning, tool use (web browsing, code execution), and handling various modalities to find a very specific exact-match answer.
Reliability & Robustness Testing
LLMs are non-deterministic. An agent might succeed at a task on Monday and fail the exact same task on Tuesday because of a slightly different token generation.
Robustness testing involves running the same benchmark multiple times (e.g., Pass@k metric) or slightly altering the prompt phrasing to see if the agent's performance collapses.
Interactive: Non-Determinism Simulator
Click "Run Task" multiple times to see how the same agent might perform on the same prompt.
Knowledge Check
If you are building an agent designed to autonomously fix bugs in an enterprise codebase, which benchmark would be most relevant to evaluate against?
Summary & Key Takeaways
- Two pillars of evaluation: Outcome metrics measure if the task succeeded; Trajectory analysis measures how efficiently the agent got there.
- Tool-use is critical: Many agent failures occur at the boundaries where the model generates parameters for external tools.
- Automated Pipelines: Use LLM-as-a-judge for scalable CI/CD testing, but maintain Human-in-the-Loop for subjective quality and safety validation.
- Standard Benchmarks: Use frameworks like SWE-bench (coding), WebArena (web), and GAIA (general reasoning) to compare models fairly.
- Robustness matters: Non-determinism means an agent must be tested repeatedly on the same prompt to ensure consistent reliability (Pass@k).
Ready for the Assessment?
You've learned the fundamentals of evaluating and benchmarking autonomous agents. Now it's time to test your understanding.
Assessment Details:
- 5 multiple-choice questions.
- You must score 80% (4 out of 5) to earn your certificate.
- Take your time; results will be shown at the end.
Click "Next" to begin the assessment.
Assessment Question 1
When evaluating an agent's task success, which of the following best describes the difference between deterministic metrics and LLM-as-a-judge metrics?
Assessment Question 2
During trajectory analysis, what specific agent behavior is indicative of an "infinite loop" error?
Assessment Question 3
A research team wants to test their new web-navigation agent's ability to interact with e-commerce sites and forums. Which standardized benchmark is most appropriate?
Assessment Question 4
Which of the following is a known limitation of using the LLM-as-a-judge approach in automated evaluation pipelines?
Assessment Question 5
Why do workflow performance metrics track "Context Efficiency"?